Learning Framework
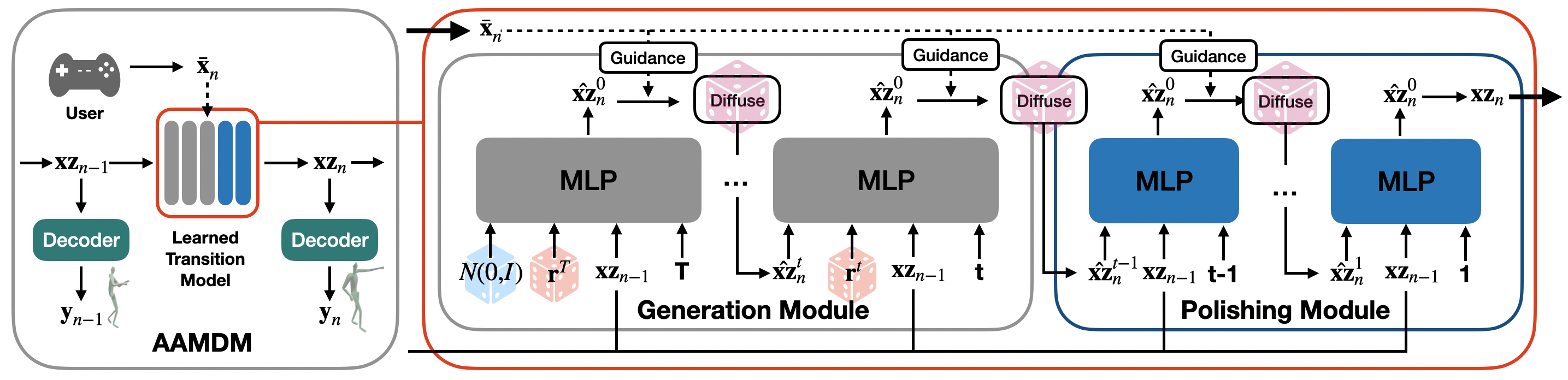
We introduce the Accelerated Auto-regressive Motion Diffusion Model (AAMDM), a novel framework crafted to generate diverse high-fidelity motion sequences without the need for prolonged reverse diffusion. Diffusion-based transition models naturally produce diverse multi-modal motion would be too slow for interactive applications. To overcome this challenge, our AAMDM framework mainly adopts two synergistic modules: a Generation Module, for rapid initial motion drafting using Denoising Diffusion GANs; and a Polishing Module, for quality improvements using an Auto-regressive Diffusion Model with just two additional denoising steps. Another distinctive feature of AAMDM is its operation in a learned lower-dimensional latent space rather than the traditional full pose space, further accelerating the training process.