Human motion driven control (HMDC) is an effective approach for generating natural and compelling robot motions while preserving high-level semantics.
However, establishing the correspondence between humans and robots with different body structures is not straightforward due to the mismatches in kinematics and dynamics properties,
which causes intrinsic ambiguity to the problem.
Many previous algorithms approach this motion retargeting problem with unsupervised learning, which requires the prerequisite skill sets.
However, it will be extremely costly to learn all the skills without understanding the given human motions, particularly for high-dimensional robots.
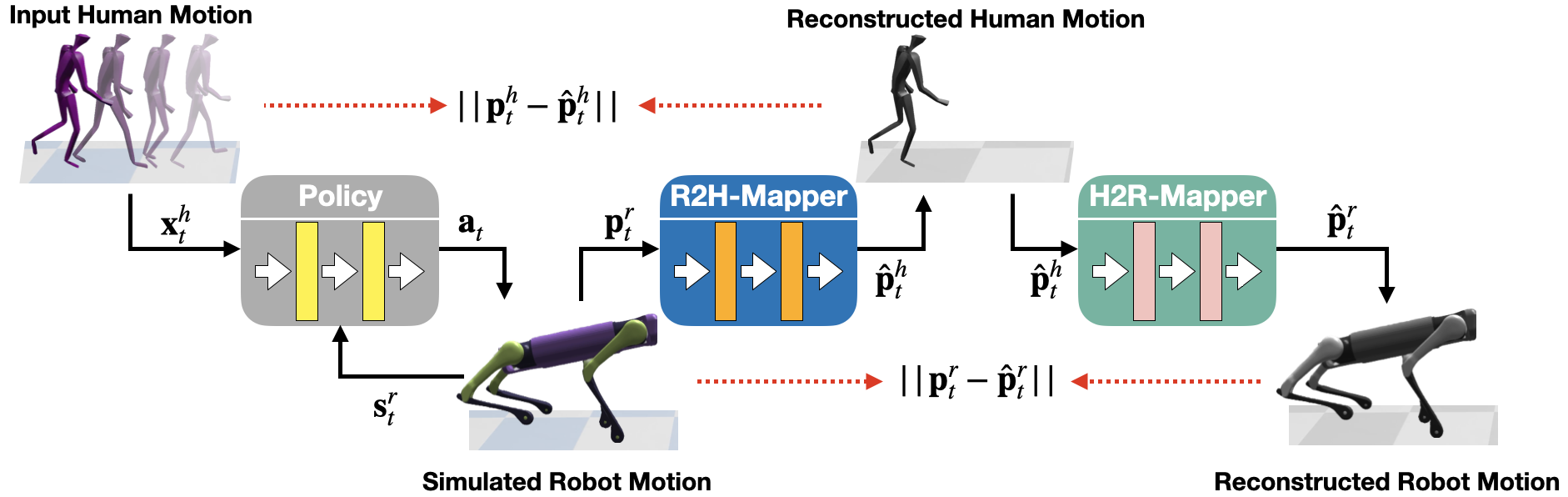
In this work, we introduce CrossLoco, a guided unsupervised reinforcement learning framework that simultaneously learns robot skills and their correspondence to human motions.
Our key innovation is to introduce a cycle-consistency-based reward term designed to maximize the mu- tual information between human motions and robot states.
We demonstrate that the proposed framework can generate compelling robot motions by translating diverse human motions, such as running, hopping, and dancing. We quantitatively compare our CrossLoco against the manually engineered and unsupervised base- line algorithms along with the ablated versions of our framework and demonstrate that our method translates human motions with better accuracy, diversity, and user preference.
We also showcase its utility in other applications, such as synthesizing robot movements from language input and enabling interactive robot control.